
강의의 최종 실습에 도착했다 *.~
🎬 대학 합격 예측 AI 만들기 🎬
🛠️ 강의용 csv 데이터 파일 다운받기 (텐서플로우를 실행하는 곳과 같은 파일에 있어야 한다)
YouTube
www.youtube.com
📍 시나리오

· admit : 0 불합격
· admit : 1 합격
· rank : 1 이 가장 높은 레벨
EX) 영어 760점, 학점 3.0, 지원한 대학교 랭킹이 2인 사람이 이 학교에 붙을 확률을 구해보자
- 텐서플로우 (keras) 가 알아서 학습해준다
- 파이썬 파일과 같은 폴더에 csv 데이터 파일을 준비해야한다
1. Keras 로 모델 만들기
1-1 딥러닝 model 디자인하기



🤚 마지막 노드는 무조건 1개 !! (출력 레이어)

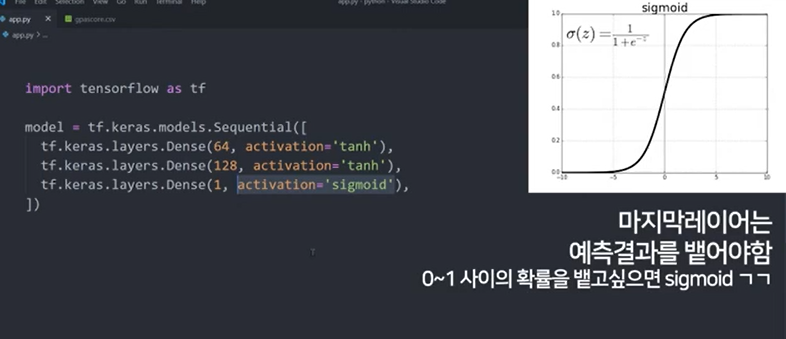
🤚 최종 확률값 출력을 위해 마지막 노드는 sigmoid 함수를 활성 함수로 지정하기 !!
1-2 model compile 하기

· 보통 optimizer 는 adam 을 사용한다
1-3 model 학습(fit) 시키기


· x 데이터 : 정답 예측에 필요한 input
· y 데이터 : 정답
2. 데이터 준비하기
2-1 데이터 파일 열기
import pandas as pd
pd.read_csv('csv 파일 이름')
2-2 데이터 전처리
→ 비어있는 부분은 평균값을 넣거나 행을 삭제한다
· 확인하는 방법
# 비어있는 행의 개수 확인
data.isnull().sum()
# NaN/빈칸 있는 행 제거
data.dropna()
# 빈칸 채우기
data.fillna(100)
· 그 외 유용한 함수
# gpa 열 출력
data['gpa']
# 해당 열의 최솟값
data[’gpa’].min()
# 해당 열의 최댓값
data[’gpa’].max()
# 해당 열의 데이터 개수
data[’gpa’].count()
· Y 데이터 만들기
# y = [정답1, 정답2, 정답3 ..]
yData = data['admit'].values→ 'admit' 세로 열에 있는 데이터 출력
· X 데이터 만들기
# x = [[데이터1],[데이터2],[데이터3]]
xData = []
for i, rows in data.iterrow():
xData.append([ rows['gre'], rows['gpa'], rows['rank'] ])→ data.iterrow() : data 라는 데이터 프레임을 가로 한 줄씩 출력하기
3. 학습시키기 & 예측해보기
· 일반 리스트를 numpy array 로 변환해야 fit 에 넣을 수 있다
3-1 학습시키기
model.fit( np.array(xData), np.array(yData), epochs=10 )→ 출력값 : Epoch(몇 번째 epoch 인지), ms/step(epoch당 소요시간), loss(현재 총손실), accuracy(모델 정답률)
→ epoch ↑이면 성능 ↑ (accuracy ↑)
3-2 예측하기
model.predict([ [750, 3.70, 3], [400, 2.2, 1] ])
🍓 내 실습 🍓
· 전체 코드
### 데이터 준비하기
import pandas as pd
# 1. 데이터 파일 열기
data = pd.read_csv('/content/gpascore.csv')
# print(data)
# 2. 데이터 전처리
data = data.dropna()
yData = data['admit'].values
xData = []
for i, rows in data.iterrows():
xData.append([ rows['gre'], rows['gpa'], rows['rank']])
### keras 로 model 만들기
import numpy as np
import tensorflow as tf
# 1. 딥러닝 model 디자인하기
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(128, activation='tanh'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 2. model compile 하기
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 3. model 학습시키기
model.fit( np.array(xData), np.array(yData), epochs=1000 )
### 예측해보기
predictData = model.predict([[750, 3.70, 3], [400, 2.2, 1]])
print(predictData)
· 출력 결과

→ 흠... 똑같은 데이터인데 난 왜 이렇게 나와?ㅋ>?
'AI' 카테고리의 다른 글
| [AI 도전기 16일차] 어떤 기준으로 사용자에게 음식 메뉴를 추천해야 할까? (2) | 2024.04.27 |
|---|---|
| [AI 도전기 15일차] 추천 시스템 최신 논문 찾기 (0) | 2024.04.12 |
| [AI 도전기 13일차] Tensorflow 2 - 키로 신발 사이즈 추론하기 예제 실습 (0) | 2024.04.10 |
| [AI 도전기 12일차] Tensorflow 2 기초 맛보기 (0) | 2024.04.09 |
| [AI 도전기 11일차] 혼공머신 강의 수강 후 내 프로젝트 중간 점검 (0) | 2024.04.08 |